| Précédent Bibliothèques | Parent Programmation sur cartes graphiques avec CUDA | Sommaire | Suivant CPU et GPU |
Nous allons continuer cette introduction avec un peu de vocabulaire inhérent à la programmation avec CUDA.
L'hôte est le CPU, c'est lui qui demande au périphérique (le GPU) d'effectuer les calculs.
Un kernel est une portion parallèle de code à exécuter sur le périphérique. Chacune de ses instances s'appelle un thread.
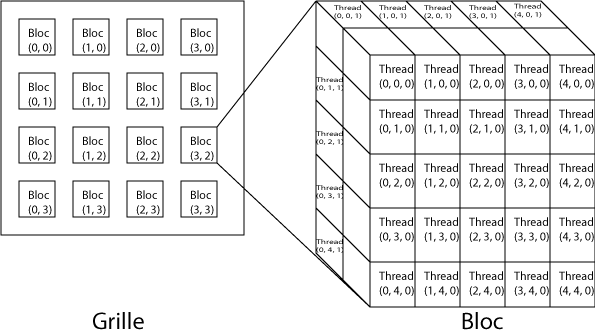
Une grille est constituée de blocs. Chaque bloc est constitué de threads.
Un bloc est un élément des calculs, dissociable d'autres blocs : les blocs ne doivent donc pas être exécutés dans un certain ordre : parallèlement, consécutivement ou toute autre combinaison est possible. C'est pourquoi les threads ne peuvent communiquer qu'avec des threads du même bloc.
Un warp est un ensemble de 32 threads, envoyés ensemble à l'exécution et exécutés simultanément. Quel que soit le GPU utilisé, quel que soit la quantité de données à traiter, dans n'importe quel cas, un warp sera exécuté sur deux cycles. On peut être sûr et certain qu'il le seront. Ceci pourra vous aider lors de la conception de vos algorithmes. Par exemple, Mark Harris, chercheur pour NVIDIA dans le rendu graphique en temps réel, fondateur du site GPGPU, utilise cette donnée pour dérouler ses boucles.
Un petit parallèle avec le matériel. Un thread est exécuté par un processeur : posons donc l'égalité entre le thread et le processeur. Ainsi, le bloc est le multiprocesseur, tandis que la grille représente l'entièreté de la carte.
Le calcul hétérogène est l'utilisation des deux types de processeur disponibles sur nos ordinateurs : les CPU et les GPU. Il s'agit donc d'utiliser le bon type de processeur pour la bonne tâche.
Vous voici prêt pour partir à l'attaque !
| Précédent Bibliothèques | Parent Programmation sur cartes graphiques avec CUDA | Sommaire | Suivant CPU et GPU |