| Précédent Mémoires | Parent Mémoires | Sommaire | Suivant Mémoire locale |
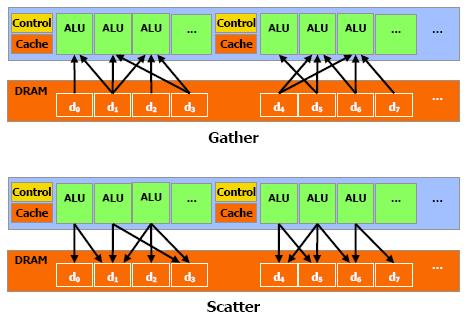
CUDA est capable de lire et d'écrire sur la mémoire embarquée dans la carte graphique. Ces opérations portent, respectivement, les doux noms de gathering et de scattering.
La mémoire globale est la mémoire utilisable de n'importe quel endroit de CUDA, avec les mêmes performances à la clé : cette mémoire n'est pas cachée et il faut attendre 400 à 600 cycles avant d'y accéder. Ce qui laisse un multiprocesseur inactif pendant ce temps.
Pourquoi une telle latence ?
La mémoire globale est, en général (dans tous les cas, jusqu'à présent), de la DRAM. Cette mémoire est très bon marché : 1,50$ en septembre 2008, pour les intégrateurs ! Ceci lui permet d'être utilisée comme mémoire principale de nos ordinateurs. De plus, elle se révèle compacte : on en fait tenir des Go sans problème sur des cartes ! Pourtant, cette mémoire a un problème et il s'agit de la latence. Elle monte sans problème jusqu'à 30 ns, ce qui représente quand même déjà 30 cycles ! Et sans compter les bus entre le multiprocesseur et la mémoire.
Finalement, cette mémoire n'est pas cachée.
| Précédent Mémoires | Parent Mémoires | Sommaire | Suivant Mémoire locale |