| Précédent Les mains dans le cambouis | Parent Les mains dans le cambouis | Sommaire | Suivant Qualificateurs de kernels |
Très simplement, un kernel est une fonction exécutée sur le GPU.
Il en existe différent types, qualifiés de :
- __global__
- __device__
- __host__
Le premier correspond à un kernel exécuté sur le GPU mais appelé par le CPU ; le deuxième, à un kernel exécuté et appelé par le GPU ; le troisième, à une fonction exécutée et appelée par le CPU. Ce dernier n'est pas obligatoire : c'est le mode de fonctionnement par défaut.
Un kernel ne s'appelle pas de la même manière qu'une fonction. Voici un appel de fonction.
Appel de fonction :
1 |
fonction(parametre, parametre); |
Mais avant de vous parler de l'appel d'un kernel, il faut que vous compreniez bien le mode de fonctionnement d'un GPU.
Une grille représente la totalité de la tâche à effectuer. Chaque grille peut être divisée en un ou plusieurs blocs, chacun exécutant plusieurs threads.
Un thread sur un GPU n'a pas le même sens qu'un thread sur le CPU. Sur un GPU, il s'agit de la plus petite subdivision de la tâche à effectuer.
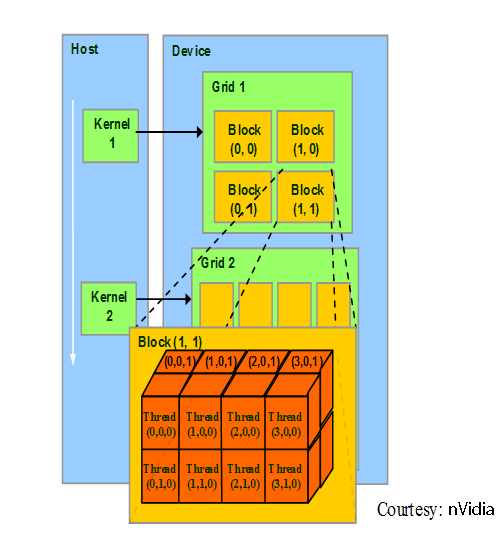
Un appel de kernel se fait en spécifiant 2 paramètres entre triples chevrons précédant les paramètres passés au kernel.
1 |
kernel <<< nBlocs, threadsParBloc >>> (arguments); |
- nBlocs est le nombre de subdivisions appliquées à la grille à calculer et est de type dim3 (le cast à partir d'un entier N initialise le dim3 à {N, 1, 1}).
- threadsParBloc indique le nombre de threads à exécuter simultanément pour chaque bloc. Ici encore, cette valeur est de type dim3.
Les valeurs à appliquer dépendent simultanément du problème à résoudre (choix des dimensions des blocs) et du matériel utilisé (nombre de threads par bloc). Choisir un nombre de threads supérieurs à la quantité nativement supportée entraînera une perte de performances. Cette notation permet ainsi d'adapter dynamiquement le programme aux matériels passés, présents et futurs.
Chaque kernel dispose de variables implicites en lecture seule (toutes de type dim3).
- blockIdx : index du bloc dans la grille,
- threadIdx : index du thread dans le bloc,
- blockDim : nombre de threads par bloc (valeur de threadsParBloc du paramétrage du kernel).
La grille est ici considérée comme un seul et unique bloc à une seule dimension.
1 2 3 4 5 6 7 8 9 10 11 |
__global__ void vecAdd(float * A, float * B, float * C){ int i = threadIdx.x; C[i] = A[i] + B[i]; } int main(){ // utilisation du kernel vecAdd<<<1, N>>>(A, B, C); // |-> vecteurs additionnés une seule fois // |-> nombre de composante des vecteurs } |
Dans le cas où la grille est sous-divisée en N blocs (tous de 1 dimension), l'index pourrait être trouvé de la manière suivante.
1 2 3 4 5 6 7 8 9 10 11 |
__global__ void vecAdd(float * A, float * B, float * C){ int i = blockIdx.x * blockDim.x + threadIdx.x; C[i] = A[i] + B[i]; } int main(){ // utilisation du kernel const int nThreadsPerBlocks = 4; const int nBlocks = (arraySize / nThreadsPerBlocks) + ( (arraySize % nThreadsPerBlocks) == 0 ? 0 : 1); vecAdd<<<nBlocks, nThreadsPerBlocks>>>(A, B, C); } |
Les variables doivent être qualifiées, pour définir leur lieu de résidence : voyez la section qui y est réservée.
Les paramètres entre chevrons sont requis, car le kernel est de type __global__. S'il était d'un autre type, ils n'auraient pas dû être précisés !
| Précédent Les mains dans le cambouis | Parent Les mains dans le cambouis | Sommaire | Suivant Qualificateurs de kernels |