| Précédent Mémoire des textures | Parent Mémoires | Sommaire | Suivant Registres |
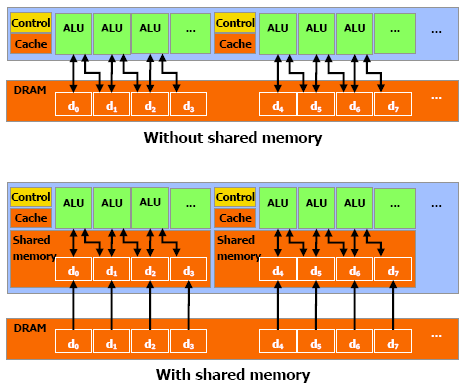
Cette mémoire est présente sur le chipset, ce qui lui permet d'être assez rapide, plus que la mémoire locale. En fait, pour tous les threads d'un warp, accéder à cette mémoire est aussi rapide que d'accéder à un registre, tant qu'il n'y a pas de conflit entre les threads.
Pour permettre une bande-passante assez élevée, la mémoire partagée est divisée en modules de mémoire, les banques, qui peuvent être accédée simultanément. Ainsi, n lectures ou écritures qui tombent dans des banques différentes peuvent être exécutées simultanément dans un warp, ce qui permet d'augmenter sensiblement la bande passante, qui devient n fois plus élevée que celle d'un module.
Cependant, si deux demandes tombent dans la même banque, il y a un conflit de banques et l'accès doit être sérialisé. Le matériel divise ces requêtes problématiques en autant de requêtes que nécessaire pour qu'aucun problème n'ait lieu, ce qui diminue la bande passante d'un facteur équivalent au nombre de requêtes total à effectuer.
Pour des performances maximales, il est donc très important de comprendre comment les adresses mémoires sont reliées aux banques, pour pouvoir prévoir les requêtes et, ainsi, minimiser les conflits.
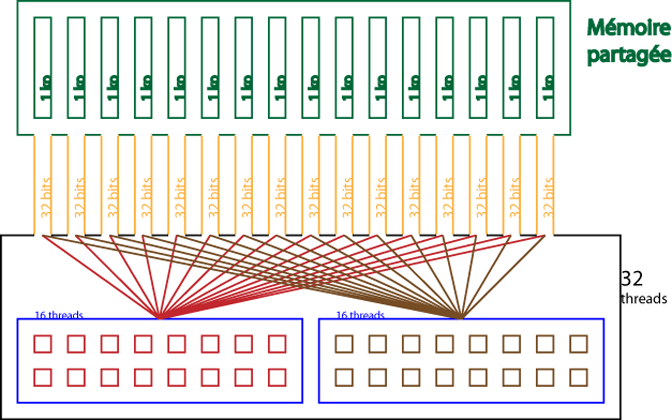
Dans le cas d'un espace en mémoire partagée, les banques sont organisées pour que des mots successifs de 32 bits soient assignés à des banques successives. Chaque banque a une bande passante de 32 bits tous les deux cycles d'horloge.
Pour le moment, un warp a une taille de 32 threads et il y a 16 banques.
Une requête en mémoire partagée pour un warp est divisée en deux : une partie pour le premier demi-warp, une autre, pour l'autre moitié. Ce qui a pour conséquence qu'il ne peut y avoir de conflit entre chaque demi-warp. Les conflits seront détaillés plus tard.
Actuellement, la mémoire partagée atteint un total de 16 ko, 1 ko pour chaque banque.
Pour résumer ceci, voici un schéma qui reprend l'essentiel des caractéristiques présentées ici.
| Précédent Mémoire des textures | Parent Mémoires | Sommaire | Suivant Registres |