4.1.2.4 : Résultats des tests de performances
La figure 4 montre les résultats des tests de performances obtenus avec GCC 9.3.0 sur un Intel® Core™ i7-7820HQ CPU @ 2.90GHz × 8 avec notre implémentation naïve.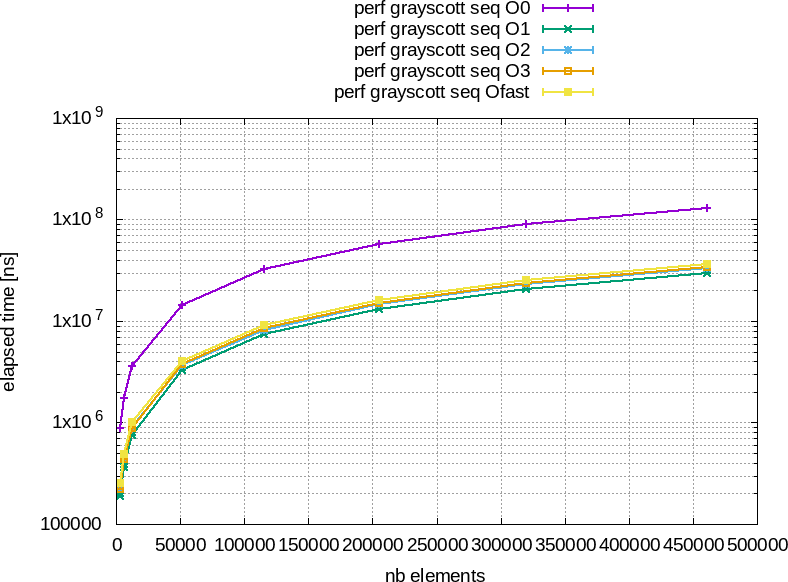
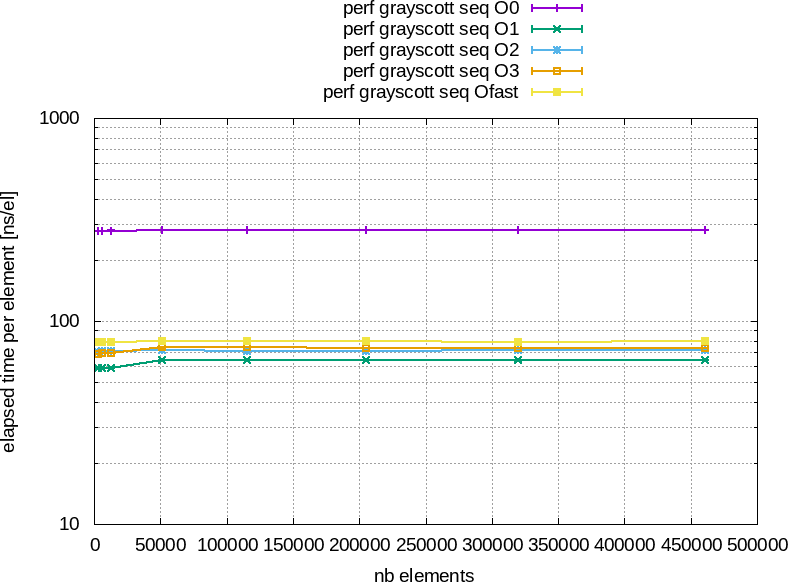
 Figure 4 : À gauche : temps total d'éxécution en fonction du nombre d'éléments à traiter. À droite : temps moyen pour traiter un élément en nano-seconde an fonction du nombre total d'éléments à traiter.
Figure 4 : À gauche : temps total d'éxécution en fonction du nombre d'éléments à traiter. À droite : temps moyen pour traiter un élément en nano-seconde an fonction du nombre total d'éléments à traiter.
Comme toujours la version compilée en -O0 est la plus lente mais ce qui est étrange, c'est que la version compilée en -O1 est plus rapide que les autres.
Il est temps de rappeler que pour des exemples où le compilateur comprend bien ce que l'on attend de lui les versions compilées en -O3 et -Ofast sont les plus rapides, ensuite celle en -O2 puis celle en -O1 et finalement celle en -O0.
Il est temps de rappeler que dans le cours Introduction to code optimisation nous abordons se sujet en profondeur très loins des affirmations infondées des uns et des autres.
Dans l'ensemble, ne vous laissez pas influencer par ceux qui vous affirment avoir raison et faites le test pour votre calcul avec des compileurs récents noteOui, ne prennez pas un vieux compilateur d'il y a 10 ou 20 ans qui sera completement à la ramasse question performance et précision, malgré ce que peuvent vous balancer certains., jouez avec les options de compilation, lisez la documentation et agissez en conséquence.
On ne le dira jamais assez, ce n'est pas la tête dans le sable que l'on résoud un problème !
Dans l'ensemble, ne vous laissez pas influencer par ceux qui vous affirment avoir raison et faites le test pour votre calcul avec des compileurs récents noteOui, ne prennez pas un vieux compilateur d'il y a 10 ou 20 ans qui sera completement à la ramasse question performance et précision, malgré ce que peuvent vous balancer certains., jouez avec les options de compilation, lisez la documentation et agissez en conséquence.
On ne le dira jamais assez, ce n'est pas la tête dans le sable que l'on résoud un problème !
Donc, pourquoi l'option -O1 permet elle d'avoir de meilleures performances ?
La réponse la plus simple est de dire qu'elle fait suffisament d'optimisations mais pas trop.
Appuyons nous sur la documentation de GCC pour y voir plus clair : https://gcc.gnu.org/onlinedocs/gcc/Optimize-Options.html
- -O0 : essaie de réduire le temps de compilation mais sans aucune optimisation. Mais -Og est meilleur pour débugger
- -O1 : propage les constantes noteCela économise des variables, supprime le code mort noteCela réduit la taille du programme et la longueur des sauts lors des appels de fonctions....
- -O2 : les fonctions sont partiellement inlinées noteSi une fonction est courte et est souvent appelée, il peut être interessant de copier directement sont code à l'endroit où on l'appelle ce qui économise un appel de fonction qui serait coùteux dans ce genre de cas., le compilateur par du principe que l'aliasing est stricte noteLa manière dont on stocke les variables dans les structure....
- -O3 : plus de fonctions inlinées, déroulage de boucle, vectorization partielle...
- -Ofast : assouplie les rêgles de conformité standard noteOn ne suis plus tout à fait le standard pour aller plus vite., active -ffast-math ce qui dégrade potentiellement la précision des calculs (là encore il convient de réagir au cas par cas et de ne pas s'offusquer à tout prix de cette option), la taille de la pile est écrite en dur à $32768$ octets (emprunté à gfortran)
Commençons par les plus simples, en ce qui concerne -O3 et -Ofast le compilateur tente une vectorization partielle. Ce qui veut dire qu'il va tenter de faire les calculs par bloc de
 valeurs contigües (ici nous utilisons des float ce qui ferai
valeurs contigües (ici nous utilisons des float ce qui ferai 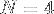 en SSE4,
en SSE4, 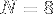 en AVX et
en AVX et  en AVX512f).
en AVX512f).Le problème de notre calcul, c'est qu'il a besoin des voisins, mais ceux-ci changent tout le temps et un bloc de
valeurs n'est pas voisin avec le suivant.
Donc, comme le postulat de contigüité est faux, l'optimisation n'est pas efficace, voire négative dans notre cas.Concernant l'option -O2, il faut fouiller un peut plus dans la documentation de GCC pour se rendre compte que cette option active le flag -fstore-merging qui optimise l'écriture des données contigües. Or, dans notre cas, les données contigües que l'on écrit proviennent de calculs sur beaucoup de données plus ou moins contigües ce qui pose problème.
Finalement, l'option -O1 s'en sort bien car elle ne se pose pas trop de questions.