5.4.2 : Comment se fait-ce ?
Récapitulons la situation :
- Nos trois programmes calculent tous $34000$ images avec le même algorithme mais implémenté différemment
- L'implémentation naïve prend : 2h 43min 30s soit $0.28$ seconde par image
- L'implémentation en fonctions intrinsèques prend : 59min 21s soit $0.1$ seconde par image
- L'implémentation en fonction intrinsèques avec des block liés prend : 9min 49s $0.017$ seconde par image
Sauf que, les benchmarks montrent que :
- Les implémentations intrisèques sont $8$ à $10$ fois plus rapide que l'implémentation naïve
- Les implémentations intrisèques sont ex-aequo
Ce qui contredit les programmes complets, où :
- L'implémentation naïve prend : 2h 43min 30s soit $0.28$ seconde par image
- L'implémentation en fonctions intrinsèques n'est que $2.75$ fois plus rapide que l'implémentation naïve alors que les tests de performances montraient quasiment un facteur $10$
- L'implémentation en fonction intrinsèques avec des block liés est $6$ fois plus rapide que l'implémentation intrinsèques de base alors que les benchmarks les placent ex-aequo
Donc, où se situe l'arnaque ?
Note : Il s'agit bien d'une arnaque et non d'un oubli ou d'une erreur, qui était parfaitement voulue, préméditée et orchestrée avec tout ce que cela implique !
Bien que l'explication ai déjà été donnée plus tôt, sinon on n'aurai pas trouver la taille des blocs, nous allons l'approfondir.
Les benchmarks tests des images entre :
- $5*5*2*8 = 400$ float soit $1.6$ko (bien plus petit que le cache L1 de $32$ko)
- $60*60*2*8 = 57600$ float soit $230.4$ko (bien plus petit que le cache L2 de $256$ko)
Or, les programmes calculent des images en HD, soit
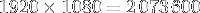 float, soit
float, soit 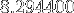 Mo (donc plus grandes que le cache L3 de
Mo (donc plus grandes que le cache L3 de 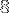 Mo)
Mo)Ces images ne peuvent donc pas être stockées dans les caches, et le rapatriment des données devient très cher en temps.
Cela implique que :
- Le programme naïf est trop lent et donc bien CPU-Band noteCPU-Band dont la vitesse d'exécution dépend des calculs
- Le programme en fonctions intrinsèques est trop optimisé et devient donc Memory-Band noteMemory-Band dont la vitesse d'exécution dépend de la mémoire
- Le programme en fonctions intrinsèques par blocs liés permet d'utiliser de nouveau les caches, et il redevient CPU-Band mais plus rapide que son homologue sans bloc
Comme les benchmarks et les programmes ne calculent pas dans les mêmes conditions, ils ont des résultats différents. Et après analyse du "Pourquoi" on se rend compte que ces résultats sont complémentaires.
La figure 13 résume les performances obtenues.
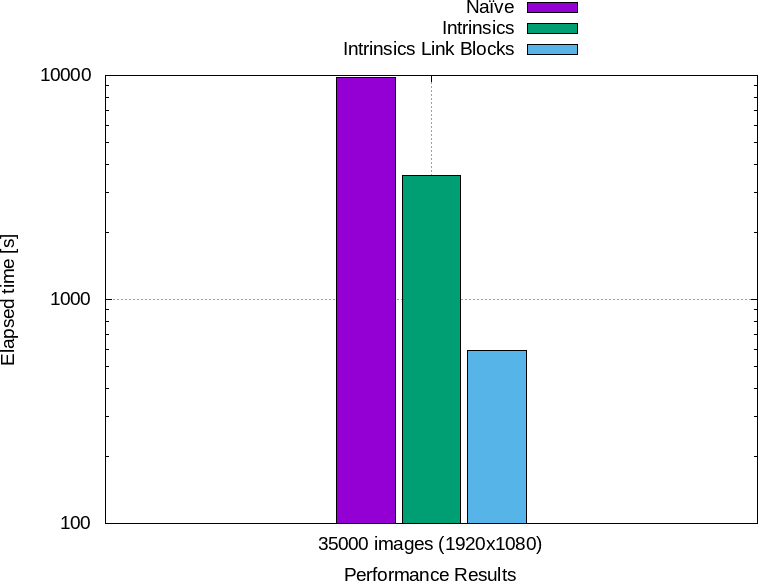
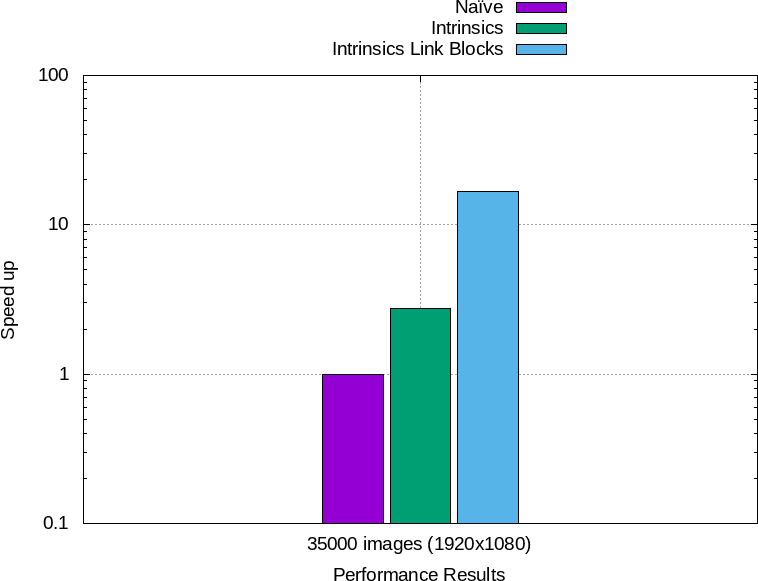
 Figure 13 : À gauche : temps total d'éxécution des différentes implémentations. À droite : accélération par rapport à la première.
Figure 13 : À gauche : temps total d'éxécution des différentes implémentations. À droite : accélération par rapport à la première.
Il est important de ne pas se faire avoir par les benchmarks fallacieux des uns et des autres qui voudraient prouver n'importe quoi : cela va du calcul très compliqué qui se fait en moins d'un cycle par élément, à ceux qui veulent à tout prix montrer que Python est un langage rapide comme si il y avait un pompon à la clé.
Faire un test de une seconde pour montrer que Python est plus rapide que Julia, c'est comme montrer qu'une deux-cheveaux démarre plus vite qu'une Ferrari : ça n'a aucun sens.
Confucius du calcul haute performance (qui préfère manifestement les Ferraris)